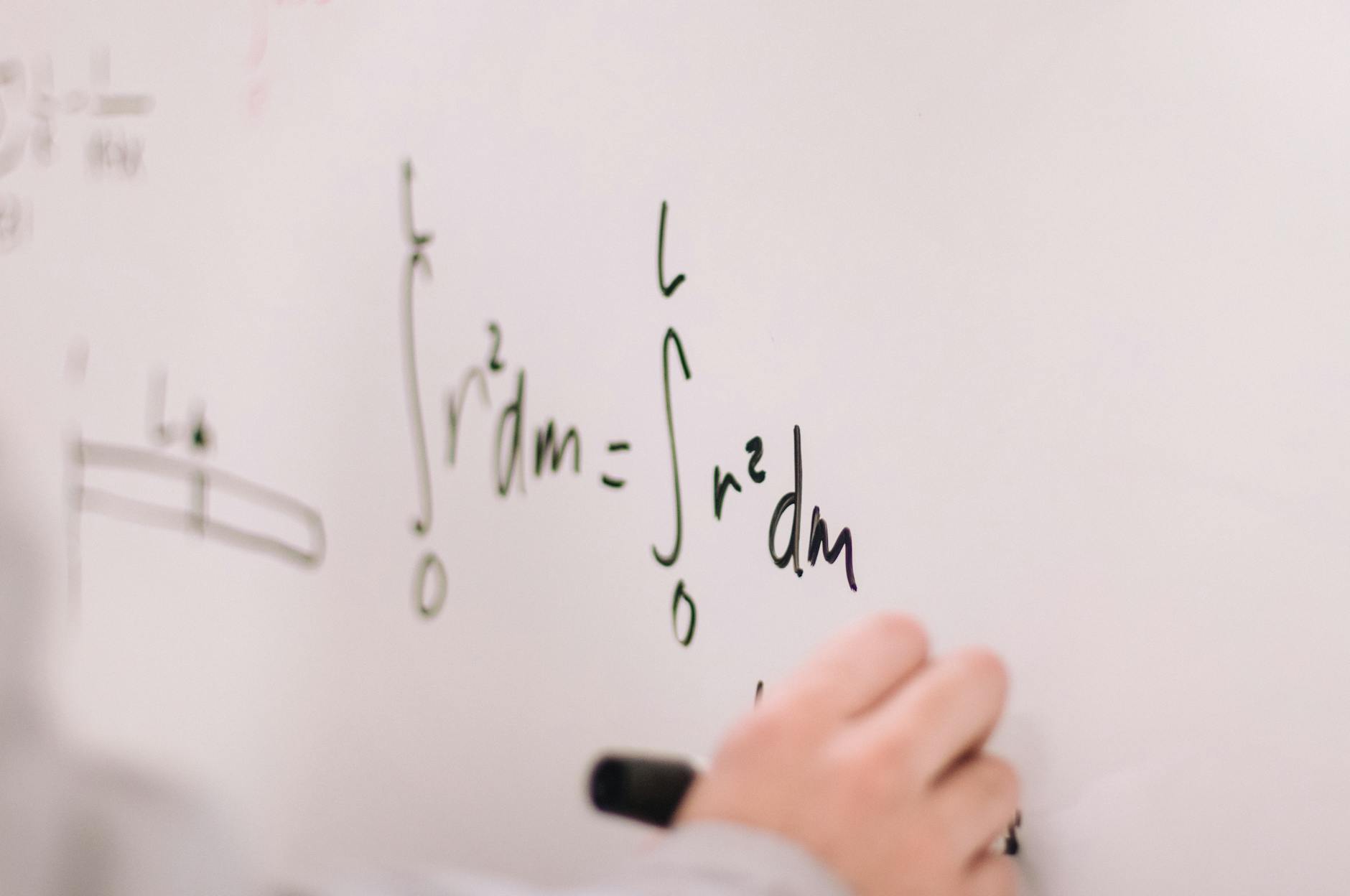
Use AI to generate tests by providing the source function, desired coverage type, and framework. Cursor, Copilot, and Claude Code can produce Jest, Vitest, pytest, and Playwright suites in seconds.
vitest, jest, pytest, @playwright/test)c8, istanbul, pytest-cov)Write Vitest unit tests for this function. Cover happy path, edge cases, and error conditions.Include tests for null, undefined, empty string, negative numbers, and Unicode.@file prisma/schema.prisma in Cursor.Create a factory function for this model using Faker.npx playwright codegen to capture selectors, then ask AI to convert to maintainable Page Object Model.pnpm test --coverage — then paste uncovered lines back: Add tests to cover these lines.Refactor using describe.each to reduce duplication.await page.waitForLoadState() — add explicitly.expect(result).toBeTruthy() passes too easily. Ask for specific value assertions.| Tool | Framework Coverage | Notes |
|---|---|---|
| Cursor | All | Agent mode runs tests, iterates on failures |
| GitHub Copilot | All | Tab-complete inside test files |
| Claude Code | All | Best for terminal-first workflows |
| CodiumAI | JS/TS/Python | Dedicated test generation product |
| Playwright MCP | E2E only | Records browser actions to spec |
AI tripled my test-writing speed without sacrificing quality. The trick is explicit prompts, iterative coverage runs, and human review of assertions. Start today — Misar Dev has built-in test generation for every language.
It's tempting to dive headfirst into complex architectures when building a RAG chatbot—vector databases, fine-tuned embeddings, and retrieva…

Practical ai text generator free guide: steps, examples, FAQs, and implementation tips for 2026.

Practical ai story generator free unlimited guide: steps, examples, FAQs, and implementation tips for 2026.





Comments
Sign in to join the conversation
No comments yet. Be the first to share your thoughts!